
Are Your Competitors Winning the AI Result Race?
GEO, generative engine optimization, is how brands rank in LLM results like Perplexity and Gemini. See how to track the way rivals get described and cited.

Contents
- The shortlist is decided in a window you cannot see
- The visibility question worth your time is how your competitors get described
- The input you already watch is where the AI answer comes from
- Run it yourself: an hour-long check on you and your top competitors
- You can watch this surface and watch what moves it, but you cannot rank in it
- What to do this week, and where a tool fits
The shortlist is decided in a window you cannot see
In a 2025 survey of roughly 4,000 B2B buyers, 6sense found that 94% of buying groups rank their shortlist before they ever talk to a seller, and the favorite they pick wins the deal about 80% of the time (6sense Buyer Experience Report 2025). 95% of the time, the winner was already on the buyer's Day One list. That decision happens early, inside the buyer's own research, before a single rep gets a reply.
That research increasingly runs through AI. In a March 2026 survey of 1,076 software buyers, G2 found that 51% now start with an AI chatbot more often than with Google, up from 29% a year earlier (G2, via PR Newswire), most often to compare vendor strengths and weaknesses (G2, via Demand Gen Report). So the comparison that hardens into a shortlist is increasingly one a model writes.
If your buyers ask an AI chatbot to compare vendors in your category, the competitor they meet first is the version a model repeats back, which may differ from the one on that competitor's homepage. A model summarizes: it picks which claims to carry, which to drop, and which rivals to name in the same breath, and the description it lands on becomes part of the pre-contact shortlist that decides roughly four deals in five.
We are a two-customer company writing this, and we sit on the same surface: when a buyer asks a chatbot which competitive-intelligence tools cost less than the enterprise ones, whatever the model says about us is doing work we cannot see. It is worth a CI team's attention, and most writing about it aims at the wrong target. The inputs that shape how AI describes a competitor are the same website, pricing, and comparison-page changes a CI team already tracks, so watching those inputs is how you watch the answer.
The visibility question worth your time is how your competitors get described
Nearly everything written about AI answers treats them as a marketing problem about your own brand, and a venture-funded tool category sells that optimization story. Search for advice and you get first-person how-to: how to get your brand cited, how to win the AI answer, how to raise your own visibility. For a competitive-intelligence reader, that is the wrong lens.
The category is real and growing fast. One AI-visibility tracker raised about $96 million at a roughly $1 billion valuation in February 2026 to help brands stay visible as AI reshapes how people find software (Fortune, 2026-02-24). That kind of money says the thing it measures has stopped being a curiosity, and G2 found that 85% of buyers view a vendor more favorably when an AI chatbot mentions it (G2, via PR Newswire). How a company gets described now carries commercial weight.
The premise is sound; the lens is wrong for a CI reader. Optimizing your own brand is a marketing job. The CI question sits one seat over: how are your competitors being described, and which comparison set is a buyer handed before a sales conversation exists? If a model names three vendors for "best tools in this category" and yours is the fourth it leaves out, the damage is done before your sales team can say a word. That is intelligence about a competitor's position, the same kind of fact as their pricing page or their hiring, and almost no one tracks it. The dedicated CI platforms have stayed quiet on it, and the AI-visibility tools aim at your own brand.

So borrow the posture a CI team already knows. Monitor your competitors here the same way you monitor their pricing pages, track your own listing as one input among them, and re-check on a schedule because the surface drifts. That works because the thing feeding these descriptions is something you can already see.
The input you already watch is where the AI answer comes from
A competitor's website, comparison page, and pricing copy is an early sign of how a model will describe them next, because that copy reaches AI answers in hours to days.
There is a documented case. In November 2025, an analyst at SEER Interactive changed his company's footer tagline from "Remote-first, Philadelphia-founded" to "130+ Enterprise Clients, 97% Retention Rate." ChatGPT began folding the new "97% retention" figure into its description within about 36 hours (Search Engine Land, 2025-11-17). New pages reached ChatGPT in about six hours, and blocking Google from a page made it invisible to ChatGPT for nine days, decent evidence that ChatGPT leans on Google's search results to decide what to say.
Read that the way a CI team would. When a competitor changes the word for what they sell, rewrites a homepage headline, or adds a retention stat to a pricing page, that wording is a draft of how an AI tool will describe them a day or two later. Those words are where the answer comes from, and watching them is how you watch the answer.
Not every change moves the answer. A site can look completely different and still say the same thing: Salesforce's June 2024 "Cosmos" refresh brought a new visual system, a fresh logo, and new photography, with almost no copy that moved, so the screenshot diff was enormous and the positioning identical, a point we made at length in Real-time alerts when competitors change their messaging. With no new wording to pick up, the model's description did not move. The changes that carry over alter what a competitor claims to be, who they say they are for, or how they frame the comparison: a rewritten headline, a new word for what they sell, a fresh pricing-page story, the framing on a "vs" page.
So the place to watch is one a CI team can already reach. The competitor's homepage, pricing page, and comparison pages are public, they change on a schedule a marketing team controls, and a copy change there previews the AI description that follows. We have not watched the full path on a tracked competitor yet, from the change we caught to the moment an AI tool repeated it, so we lean on the SEER test rather than claim a Meertrack figure.
This is the narrow place a change-monitoring tool fits. Meertrack catches that copy change the day it goes live and shows the before-and-after wording word for word, with the page and the date, so you see the exact line a model is about to repeat. It reports what changed on the competitor's site; the AI's answer stays out of scope. The value is the head start: you see the source change before the AI tools have finished repeating it.
Catching the change is half the job. The other half is the answer itself, which you can check by hand on yourself and your top competitors in about an hour.
Run it yourself: an hour-long check on you and your top competitors
You can baseline how AI answers describe you and your competitors in about an hour, with a fixed prompt set, five AI tools, and one spreadsheet. Put your competitors in the subject column and your own listing as one row among them. The question worth an hour is how each competitor gets described, which comparison set the model volunteers, and which sources do the describing.
The prompt set, the tools, and the spreadsheet columns
Write 10 to 15 prompts a buyer would actually type, in their words rather than your marketing language, across three families. Category: "best [category] tools in 2026," "best [category] software for a [industry] team." Comparison: "[competitor A] vs [competitor B]," "alternatives to [competitor A]." Persona: "what should a [job title] look for in a [category] tool." Comparison and persona prompts most often produce a ranked shortlist, so weight your set toward those.
Open ChatGPT, Claude, Perplexity, Gemini, and Google's AI answers in five tabs and treat each as its own place to check, because they pull from different sources and a competitor can lead in one tool and go unmentioned in another. One analysis found only about 11% of the websites ChatGPT cited were also cited by Perplexity, a rough figure rather than a settled one, but it points the right way (Authority Tech, 2026). Run identical wording across all five so the results compare cleanly.
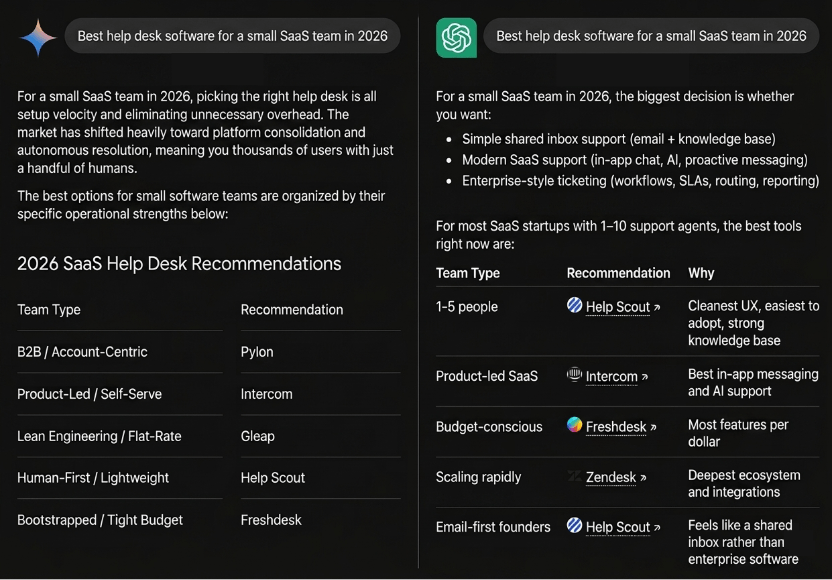
Log one row per prompt and tool, with columns for: named (yes or no), position (first, middle, or buried), whether it linked to a source and which site, the exact wording used to describe the vendor, the competitors named alongside, and any error in pricing or features. Score each 0 to 3, where 3 is a first mention with a working citation and 0 is no mention. That score makes drift visible: a number sliding from 2 to 0 between runs is something you see at a glance.
Account for randomness, then click the citations
Ask the same question twice and you can get two answers, so run each key prompt at least three times and record how often you show up as a fraction. "Named first in 2 of 3 runs" is a real reading; one run is noise dressed as a finding. The result shifts with wording, time of day, and which tool you ask.
Add a weakness probe for yourself and each competitor: "what are the downsides of [vendor]," "common complaints about [vendor]." When a negative comes back, click the citation and read the page the model leans on, because that page (a review, a forum thread, a comparison article) is what actually shapes the description. Analyses disagree on how much describing comes from third-party pages versus a vendor's own site, and the split is contested and query-dependent: one puts third-party sources high, another puts a brand's own domains in front (Semrush). Clicking the citations is how you find out which holds for your category this week.
Sort the findings: competitor errors are intel, your own errors are a fix-list
Sort the full spreadsheet into two piles. Rank the competitors by who gets named first and most often, a rough read on how loudly each one shows up. Then separate the errors. A model quoting a competitor's old price, describing them by old positioning, or pairing them with the wrong rival is intel: their site or listings have not caught up, and you can see where the model's picture is stale. The same error about you is a fix-list, a wrong claim a buyer may act on without checking your real pricing page.
A paid category automates this loop across the tools on a schedule. The manual pass is the free way to see it first and decide whether continuous watching is worth paying for, on your own evidence rather than a vendor's pitch. One pass gives you a baseline and a sorted list of findings. It does not hand you a dial to turn, and the reasons why are worth spelling out before you mistake an hour of sampling for control.
You can watch this surface and watch what moves it, but you cannot rank in it
This surface gives a different answer to the same question, the models get prices and features wrong and sometimes invent them, they pull from sources you do not own, and there is no dashboard that shows your rank, only spot checks. Anyone selling you a clean number is selling you false precision.
Start with the wobble. The same prompt returns different answers from one run to the next, at different times of day, with small changes in wording, even depending on where the request is handled (How AI Models Work, Feb 2026). That is why the manual check records a fraction instead of a yes or a no: you are reading a range of possible answers, and that range shifts under you.
Then there is what the model gets wrong. AI answers quote old prices from a saved copy of a page, invent features a product does not have, pair a vendor with the wrong competitor, and describe a company that changed direction last year by its old positioning. As a buyer builds a shortlist, a wrong answer there can cost you the deal. When the Tow Center at Columbia tested eight AI search tools on 1,600 queries, the tools returned a wrong answer more than 60% of the time, and the paid ones were often more confidently wrong than the free ones: Grok 3 missed 94% of queries while free Perplexity missed 37% (Columbia Journalism Review, 2025). The stakes are real: Air Canada was held liable in 2024 after its chatbot stated a bereavement-fare policy that did not exist, setting the precedent that a company can be accountable for what its AI says. A wrong answer about a competitor is intel; the same about you is a problem you may never see, because the buyer who reads it rarely tells you.
The sources move too. One tracker reports that a large majority of the sources cited in AI answers can change over months, so the page describing a competitor today may be gone next quarter (Fortune, Feb 2026). Many are sources you do not own and cannot edit, which is the same reason there is no setting to change and no rank to climb. Buyers feel the unreliability: per Gartner, via secondary coverage, roughly half say they are more likely to hit misleading information from generative AI, and most still validate with a human rep before they commit (Demand Gen Report, May 2026). The AI answer sets the comparison set and the first impression; the rep gets a chance to correct the record, if the deal reaches a rep at all.
So here is the plain version: you can sample this and watch what moves it, and there is nothing to rank in. No dial to set, no score to optimize, because it is a shifting mix of answers pulled from sources outside your control. Take a reading on a schedule, and watch the copy changes that feed the next one. That is where a tool can do the upstream half for you without overstating what it can see.
What to do this week, and where a tool fits
How a competitor is described in an AI answer is a competitive surface buyers meet before they reach a sales rep, fed by the same site, pricing, and comparison-page changes a CI team already tracks. The shortlist hardens before any conversation you get to have, and the copy behind the version a model repeats is sitting on a page you can read today.
So do the cheap thing first. Run the manual check on yourself and your top competitors this week, then re-run it after either you or a competitor changes a homepage, pricing page, or comparison page. An hour of sampling tells you which competitors get named first, where an answer repeats a stale price, and which source is doing the describing. For the cost of a morning, you will know more about this than most of the category does.
Once that pass shows you it is worth watching, the question is who catches the competitor's change the day it goes live rather than the next time you sit down to check. Meertrack catches the messaging, pricing, and comparison-page change that moves the answer next, and shows the before-and-after wording word for word, the exact line a model is about to repeat. If you have a more technical teammate, Meertrack also offers an API and an open-source MCP server, so a developer can point an AI assistant straight at your competitor-change feed.